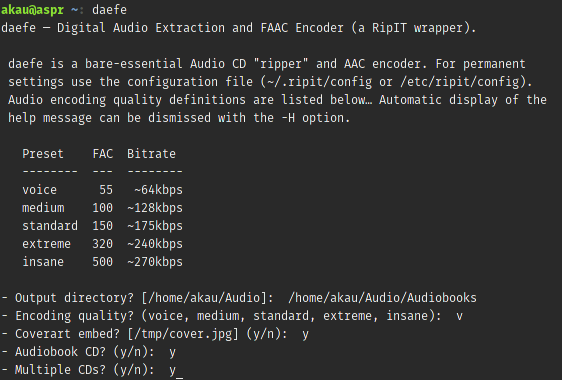

The Arch Linux BBS has a thread where people put up their scripts so that others can peruse them. A long time ago someone came up with the idea to create a script that would detect various archive formats and decompress them. That post is unfortunately gone now, but I kept the idea and have expanded on it a bit: I’ve added a couple archive types, file detection, program detection, and archive list support. I gave it a good, overall test so I feel comfortable with it.
Options can be in any order:
$ decompress archive-r.zip --help decompress [*-l] ... — wrapper script to decompress various archive types -l, --list - list archive contents
If an archive’s existence isn’t detected it will be displayed:
$ decompress archive-r.zip archive non-existent: archive-r.zip
If a program’s existence isn’t detected it will be displayed:
$ decompress archive-q.zip program required: unzip
Listing support is available:
$ decompress -l archive-q.zip
archive-q.zip
32 2016-04-11 10:39 file-q1
32 2016-04-11 10:39 file-q2
Listing and decompressing can be done for multiple documents:
$ ls archive-a.tar.bz2 archive-f.tgz archive-k.txz archive-p.xz archive-b.tb2 archive-g.tar.lz archive-l.7z archive-q.zip archive-c.tbz archive-h.tar.lzma archive-m.bz2 archive-d.tbz2 archive-i.tlz archive-n.gz archive-e.tar.gz archive-j.tar.xz archive-o.lz $ decompress archive-* archive-a.tar.bz2... archive-b.tb2... archive-c.tbz... archive-d.tbz2... archive-e.tar.gz... archive-f.tgz... archive-g.tar.lz... archive-h.tar.lzma... tar: This does not look like a tar archive tar: Exiting with failure status due to previous errors archive-i.tlz... tar: This does not look like a tar archive tar: Exiting with failure status due to previous errors archive-j.tar.xz... archive-k.txz... archive-l.7z... archive-m.bz2... archive-n.gz... archive-o.lz... archive-p.xz... archive-q.zip...
.exe and .rar files are untested because I was lazy. If there is an error its error message will be displayed.
decompress can be found in my general-scripts repository.